Big Data: The 10 Big challenges that are hindering its adoption
“After more than 50 years, the Computer Age as we’ve known it is ending. And what will replace it — perhaps we will call it the Informatics Age — will be a kind of Copernican Revolution in knowledge. That is, humans will no longer be the center of the data solar system, with all of the billions of devices orbiting around us, but will rather become just another player, another node, in an increasingly autonomous data universe.”
— Esther Dyson, in The Human Face of Big Data
Rick Smolan, who has put the book together, along with Jennifer Erwitt, states in his foreword, “During the first day of baby’s life, the amount of data generated by humanity is equivalent to 70 times the information contained in the library of Congress.” We are talking about Big Data. How much Big Data is out there? No one really knows the exact figures as the data is humongous and growing by the second. Some estimates, as by IBM, put the figure at 2.5 quintillion bytes of data being created everyday. IDC predicts that we would have generated 40 zettabytes of data by 2020. This data comes from everywhere: posts on social media — texts, photos, videos, sensors used in IoT (some say that IoT and Big Data are two sides of the same coin) sensors used in cars, sensors used to gather climate information, purchase transaction records, GPS signals, smartphone data, to name a few. While ‘How do we use the Big Data?” is another question, when in reality, we are just scratching the surface of Big Data and its 3 Vs — Volume, Velocity and Variety. There are challenges. Let’s try and identify the 10 biggest challenges hindering the possibilities of Big Data.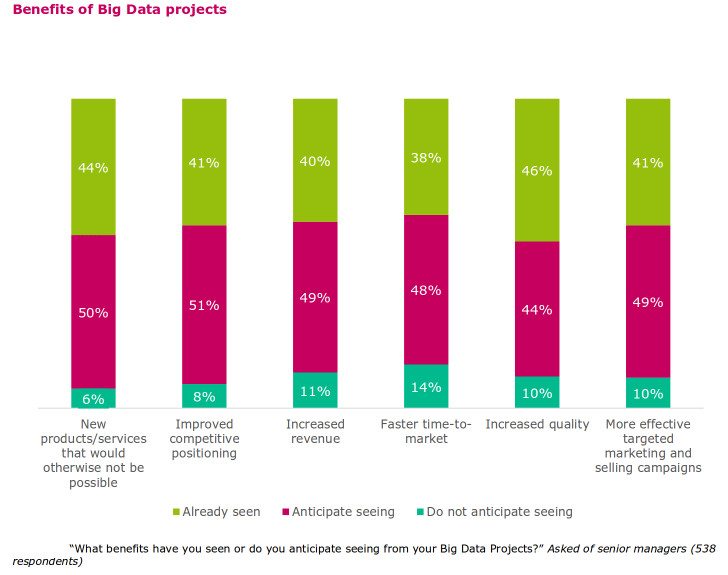
1. Infrastructure
According to a study — The State of Big Data Infrastructure — commissioned by CA Technologies and done by technology market research firm, Vanson Bourne, the amount of data coming into and through organizations increased by an average of 16% in 2013 and 2014. This is set to rise by a further 24% in 2016 and 2017. But the figures could be much larger for businesses built around customer data. The Internet of Things, though in its infancy, will add even more. Where do you store this Big Data and how do you store this Big Data is a big challenge. The challenge Infrastructure poses can be broken into ‘storage’ and ‘how data is stored’. The deployment of Big Data analytics tools inside organizations has been largely organic. Analytics tools are being deployed in silos alongside traditional IT infrastructure. In many situations, companies run multiple node clusters. While analytics engines like H2o and Naiad are agile solutions and do a good job of combining the data, this makes it difficult to deploy and maintain a single and manageable central cluster. Some vendors are using increased memory and powerful parallel processing to crunch large volumes of data extremely quickly. Another method is putting data in-memory but using a grid computing approach, where many machines are used to solve a problem. One scalable solution of course is embracing the cloud. But not all companies are ready for the cloud due to technology legacy issues. Companies are working hard to find other solutions to the storage problem. IBM is working on ‘Cognitive Storage‘ to teach computers what to learn and what to forget. The idea envisages that computers can be taught to learn the difference between high value and low value data i.e. memories or information, and this differentiation can be used to determine what is stored, on which media and for how long. Redundant data can thence be discarded. Meanwhile, there are analytics companies that are working on data optimization. Splunk, recently, released version 6.4 of its lead on-premise software Splunk Enterprise, that claims to reduce storage costs of historical data by 40 percent to 80 percent, whether deployed on-premises or in the cloud. The company claims that a customer indexing 10TB of data per day, with a data retention policy of one year, may save over $4 million of storage costs over five years with Splunk Enterprise 6.4.2. Budgets
While CIOs realize the benefits of Big Data, they find it difficult to convince the CFO and justify the ROI on Big Data. Projects are becoming more costly. According to the CA Technologies report mentioned earlier, existing Big Data projects are costing organizations 18 percent of their overall IT budget, on average. This is expected to increase to 25 percent in three years’ time. Budgets remain a big constrain in the growth of Big Data. Almost all (98%) respondents admit that major investments are required to allow their organizations’ Big Data projects to work well.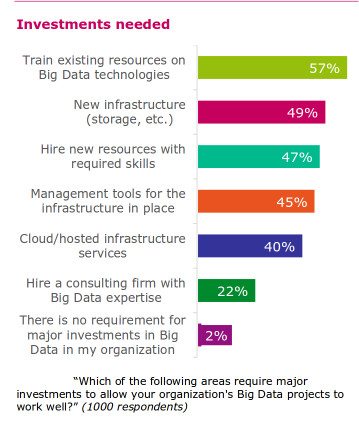 This includes investing in people, including training existing resources (57%) or hiring new staff with the required skills already (47%). But two fifths of respondents report that their organizations also need to invest in new infrastructure (49%), management tools for infrastructure already in place (45%) or cloud/hosted infrastructure services (40%).
This includes investing in people, including training existing resources (57%) or hiring new staff with the required skills already (47%). But two fifths of respondents report that their organizations also need to invest in new infrastructure (49%), management tools for infrastructure already in place (45%) or cloud/hosted infrastructure services (40%).
3. Search
More than 80 percent of today’s information — things like customer transaction data, ERP data, documents, contracts, machine data, sensor data, social media, health records, emails, images, videos — is unstructured and it is typically too big to manage effectively. Imagine this data not in gigabytes, but in terabytes, petabytes, exabytes, zettabytes and so on. The challenge is discovery — how to find high-quality data from the vast collection — and that too at good speed. There are two alternatives: Using opensource tools like Apache Solr within Hadoop or implementing a proprietary full-text search engine. A lot of people use Hadoop as a sort of data refinery for unstructured data, which cleans, transforms, and structures the data, and shipping it into SQL databases where it is subsequently analyzed. While it leads to duplication of data — one clean and one unstructured, it also takes days and months to search that data. Brajesh Sachan, CTO of Deskera, a Singapore headquartered, enterprise software company, tells that there are two types of data — structured data and unstructured data. Structured data is usually available in relational databases from which the relevant information can be retrieved very easily using Structured Query Language (SQL). “The challenge arises, when you have all this data lying around unstructured. How do I retrieve the relevant data when I need it?” Sachan asks, adding, “One way to do that would be to index all of it and search using keywords the way you do it on the web (read Google). The question here is what are the relevant keywords now that I should apply?” If the organization is large, and data is lying on personal computers — in emails, in folders, in ERP, on network servers, on cloud, data searching becomes time consuming, which could take days, and even weeks. Once you get the results, how do you get actionable insight from that data in less time? Palo Alto, CA, based Cloudera, offers a Google-style search engine for Hadoop, called Cloudera Search. The tool, based on Apache Solr, integrates with the Hadoop Distributed File System or with Hbase. Users can type what they’re looking for and get a list of results — just as they would with a Google search. For competition, Cloudera Search has MapR and Lily Project. Traditionally, a desktop search tool, X1 recently, released its enterprise based big data search tool — X1 Distributed Discovery (X1DD). It can search across desktops, laptops, servers, or even the Cloud; and has the capability to look for any kind of data — emails, files, attachments, or any other information. John Patzakis, Executive Chairman, X1, says, “X1DD provides immediate visibility into distributed data across global enterprises within minutes instead of today’s standard of weeks, and even months. This game-changing capability vastly reduces costs while greatly mitigating risk and disruption to operations.” Meanwhile, Google introduced its cloud-based big data service, last year, which it claims is twice as fast as those of competitors. In a blog post, Cory O’Connor, Product Manager, Google, states that SunGard, a financial software and services company, already has built a financial audit trail system on Cloud Bigtable, which is capable of ingesting a remarkable 2.5 million trade messages per second.
Meanwhile, Google introduced its cloud-based big data service, last year, which it claims is twice as fast as those of competitors. In a blog post, Cory O’Connor, Product Manager, Google, states that SunGard, a financial software and services company, already has built a financial audit trail system on Cloud Bigtable, which is capable of ingesting a remarkable 2.5 million trade messages per second.
4. Visualization
Much of this data is granular. So how do you put the data into context and make sense of it? Mining millions of rows of data is a big headache for analysts tasked with sorting and presenting data. Organizations often approach the problem in one of two ways: Build “samples” so that it is easier to both analyze and present the data, or create template charts and graphs that can accept certain types of information. Both approaches miss the potential for big data.
5. Legacy
When it comes to legacy, the challenges are two-fold: ‘legacy culture’ and ‘legacy architecture’. Adopting number and evidence-based decision making is a cultural shift. It demands unlearning and learning of work processes. It demands scrubbing of data, adoption of new technologies, and training of employees. All this demands investments, which could become a hindrance. Even if not, compatibility of new and old technologies could become an issue. Let’s accept it, older processors cannot handle Big Data. Add to that multiplicity of data points. IDC points out in a recent white paper: “Most organizations today have multiple data warehouses, data marts, data caches, and operational data stores. One of the reasons why many of these organizations struggle to deliver value from data is because of the number of possible integration points among the number of different data management and analysis technologies. Where to start or how to proceed is not always clear. The hype surrounding Big Data in recent years has spread an increased sense of confusion about the technology and the process for deriving value from data.” The good news is that data companies are working to bring solutions to integrate data. Take for example, Teradata. It claims that its big data architecture software, Teradata Unified Data Architecture, “allows organizations to capture, deploy, support, manage and seamlessly access all their data from multiple data platforms.” Claudia Imhoff, author and consultant in Business Intelligence and data warehousing, says: “When you bring together both the old and the new technologies, you gain additional analytic opportunities beyond what you can realize with any one of them separately. For instance, when you bring together the Enterprise Data Warehouse and Operational Analytics, it’s possible to do things like stock trading analysis, risk analysis, and discovery of the correlation between seemingly unrelated data streams, like things you never been able to do in the past such as see a link between weather and the success of a marketing campaign. This is where you can use a fraud model against streaming transactions to determine whether a transaction has the characteristics of fraudulent transactions. If it does, then it can be dealt with very quickly.” The key is to focus on the opportunities and rewards of Big Data initiatives rather than getting stuck in endless discussions about technology. The technologies supporting this space are evolving so fast that investing in capabilities is more important than investing in individual pieces of hardware and software. But if you have the budgets, and are willing to shun the old for the new, or if you are just starting out, cloud could be the best solution. Cloud makes big data so much easier.6. Location
In July 2014, a US District Court judge demanded that Microsoft make available some customer emails to government investigation agencies. Microsoft contested that the since the emails were on Ireland servers, the government’s request cannot be entertained as the data was subject to Irish law and that the government should go through law enforcement treaty channels to obtain the data.
7. Security
Snowden effect, the Panama Papers, Sony data breach, all are some examples of data theft. Huffington Post has collated 32 cases which were bigger than the Sony data breach in 2014-15. Market research company, Argus Insights, studied over 2.3 million social mentions that make up the Twitter discussion about IoT between January and April 10 this year. The report shows that among IoT topics addressed in the social conversations, Big Data leads market mindshare, since growth in Big Data is a natural byproduct of the IoT (all connected devices collect vast amounts of data). Amidst all, it is security concerns that predominate, showing significantly more social mentions than privacy concerns.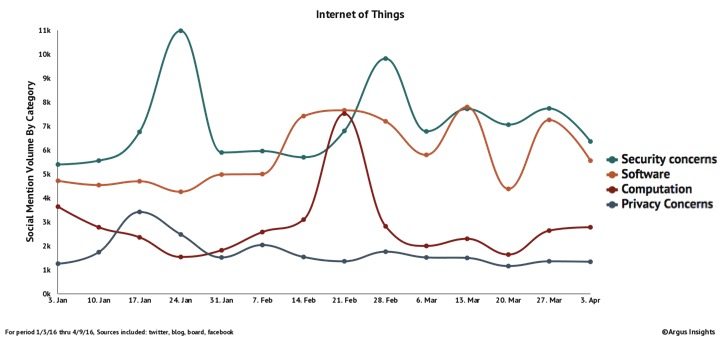 Companies need to invest into countermeasures such as encryption, access control, intrusion detection, backups, auditing and other corporate procedures, which can mean not only lot of hassle but lots of money too. Despite things in place, all these measures throw up a new challenge? Privacy. It provides legitimate excuses for companies and governments to collect more private information such as employees’ web surfing history on work computers. Governments can collect information in the name of improved security and everyone is under the scanner and watched at with suspicion.
Companies need to invest into countermeasures such as encryption, access control, intrusion detection, backups, auditing and other corporate procedures, which can mean not only lot of hassle but lots of money too. Despite things in place, all these measures throw up a new challenge? Privacy. It provides legitimate excuses for companies and governments to collect more private information such as employees’ web surfing history on work computers. Governments can collect information in the name of improved security and everyone is under the scanner and watched at with suspicion.
8. Who owns Big Data?
All this leads to a bigger question: Who actually owns the big data? The consumer or the company that collected it and has invested huge amounts of money into data infrastructure; and who use the data to make more money either using insights and incorporating them into their sales strategies or by selling the data to third-parties? What share does the consumer get? There are data banks like Wikipedia which are not-for-profit and collate data for the larger public interest and are free. The question is not as simple as it sounds. It has many layers to it. Think of a company that brings in data from outside and integrates it into its own processes. Does the company own the data now and is allowed to resell it? Or is it that it’s just got the license to use it for its own profit? There are startups that of course are giving the consumer the right to claim their data and monetize it. HAT is one such example, which is allows consumers to claim their data by seeing what organizations like Facebook, Google, broadband providers, supermarkets, online stores, streaming services and transport providers and more know about you. Once the data is claimed, it can then be traded off with businesses for financial and product incentives. Take another example of Farmobile. Why does it exist? Its website states: “From Big Ag to Silicon Valley and back again, the race to gather farm data is on. Some genetics companies, equipment manufacturers and freemium startups want an informational edge to target your margin. It’s time to protect your data like the significant asset it really is. Own your data. Own your relationships. Own your margins. We exist to believe in #FarmerPower.”